Research topics
Novel Data Compression algorithms (JP)
The Data Compression area is more and more important with the still growing volume of any type of data. The current algorithms are mostly designed as general with acceptable compression ratio for any type of data. The maximum compression is usually achieved with the specialized algorithm designed for concrete data and concrete purpose. The design of a novel algorithm for the specialized data type is a current problem and it is deeply investigated around the world. The purpose is to define an algorithm for DNA, Text, XML or video which will achieve the best compression ratio or will enable another functionality such as fast indexing, searching without decompression etc.
Novel similarity measures and meaning mining for textual data (JP)
Measuring of similarity is very difficult task especially when a text is taken into account. The text has more complex structure than simple vectors and, therefore, its more difficult to analyze similarities. Moreover, the text allows more operations which slightly change the structure but not the meaning, e.g. word swap, paraphrasing, etc. This complicates the algorithm design. We designed a novel algorithm based on data compression, but more ways are still open. Additionally, a closely related problem of text meaning mining is also very difficult. A nice approach based on the quantum information were designed, but they are so complicated that it was not possible to use them in the past, Nowadays, we may utilize a GPU computation cores or MIC architecture to speed-up the computation and bring this approach into real problem solving.
Human-Computer Interaction (MR)
![]()
Generally, Human-Computer Interaction (HCI) covers the design and use of computer technology by humans, mainly focused on the interfaces between people and computers/applications. The main tasks are to observe the ways in which humans interact with computers and design technologies that allows humans interact with computers. Nowadays, the HCI is very popular topic, not only in research area but also in case of common user applications. Even if HCI covers all forms of interaction (including regular interaction with keyboard, mouse, screen, etc.) current IT approaches and technologies bring more sophisticated inputs (actuators) and outputs (senses) in new ways. For example, this is illustrated by products like HoloLens, Kinect or Oculus.
Our research in this area is mainly focused on the actuators part of HCI. It means we are interested in analysis of user’s behavior that leads to interaction and generates data for controlling of the applications, evaluating the software usability as well as monitoring of the user’s physiological manifestations. We use technologies of Eye-Tracking and Noninvasive Analysis of Brain Waves (EEG) for these purposes. Both of these approaches can be used as data collection tool (further analysis, pattern searching, evaluation of user’s behavior, etc.) as well as input device and direct control medium (substitution of conventional input devices, combinations with other actuators, etc.). In our research we try to use this approaches for collecting data and its analysis as well as for controlling computer software. The novel approach is also based on mix of these two approaches to cover wide amount of human based data and relation between them.
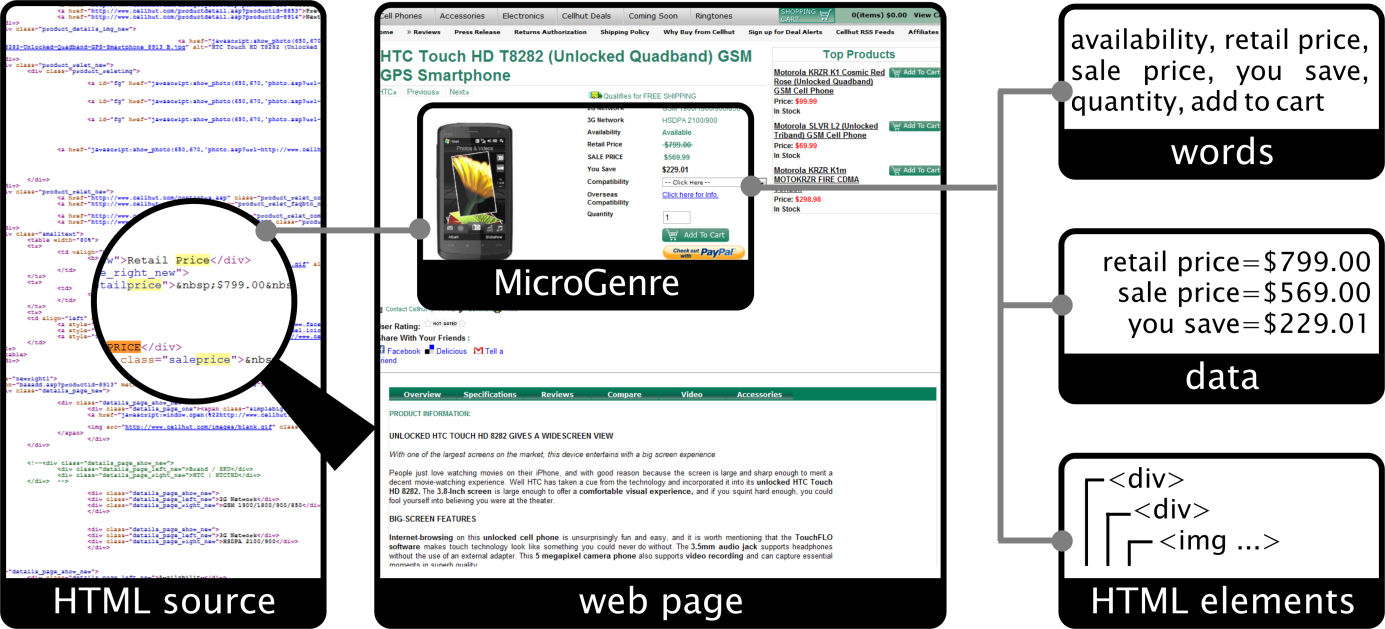
Web Content Mining (MK)
In Web Content Mining research area, the effective analysis of web page contents which is related to human aspects of the perception of web pages is one of the most important tasks. In this area, long-term research is conducted, and the main results are:
- A novel view of the structure of web pages using so-called MicroGenres
- The Pattrio segmentation method and a meta-search engine
The methods proposed in the research were also used for a unique analysis of the similarity of websites.
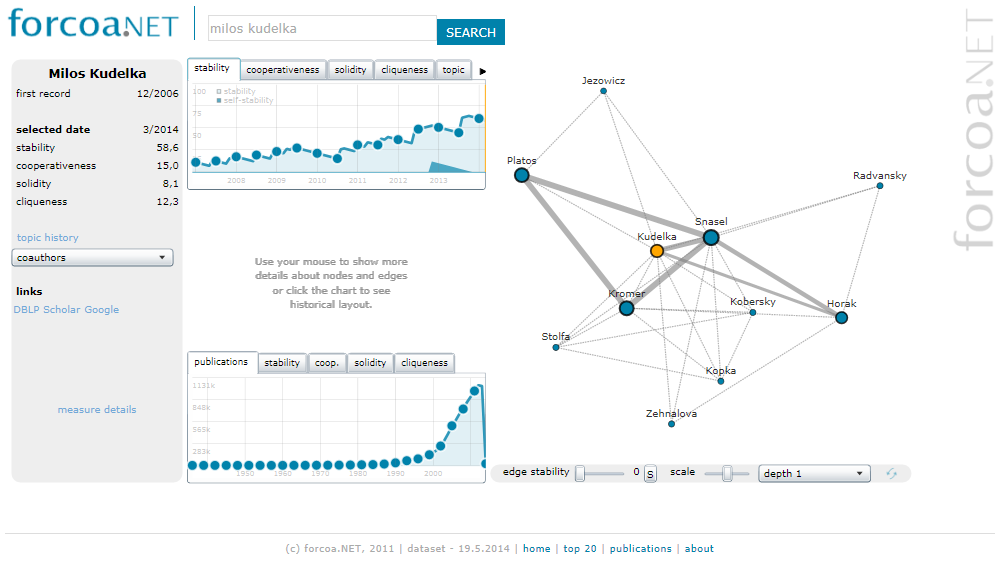
Analysis of Big Social Data (MK)
Analysis of big social data aims to study large-scale Web phenomena such as social networks from a holistic point of view. Research activities in this area focus on the analysis of network evolution, detecting egocentric structures and communities and their evolution over time. Main results are:
- New methods of identifying significant vertices and relationships in networks
- Novel approaches to reduce large-scale evolving networks while maintaining their topological properties
Most of the proposed methods are applied in on-line tool Forcoa.NET focusing on visualization of large-scale co-authorship network and, in TeamNET system that is focused on analyzing email communication of small teams.

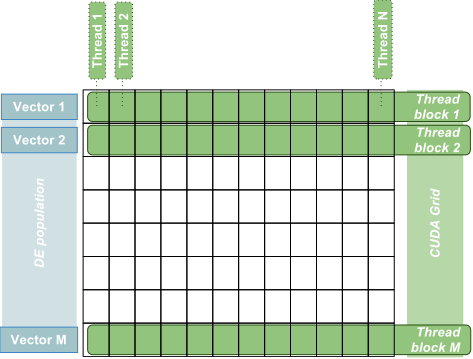
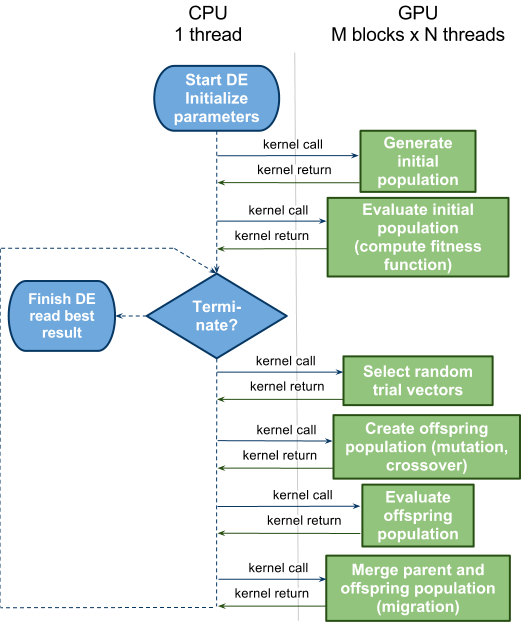
General Toolkit for Large Scale Data Analysis (PG)
Processing large datasets generated by research or industry represents one of the most important challenges in data mining. Ever-growing datasets present the opportunity for discovering previously unobserved patterns. Although analyzing data is the major issue of data mining, general processing of large data can be extremely time consuming. Bio-inspired computations provide a set of powerful methods and techniques based on the principles of biological, natural systems, e.g. evolutionary algorithms, ant colony, neural networks, swarm intelligence, etc. that complement the traditional techniques of data mining and can be applied in places where the earlier approaches have encountered difficulties. Bio-inspired methods have been successfully applied in various research areas from software engineering and data processing to chemical engineering and molecular biology. The main goal of this project consists in the implementation of powerful bio-inspired methods and algorithms for data mining that will reflect current trends in data processing and hardware evolution.
Current state of the applications
- Fast GPU implementation of selected bio-inspired methods
- Visualization toolkit
Signal Data Processing (PG)
Human-Computer interaction is a very important issue that has been addressed in many ways. The Brain Computer Interface (BCI) is an attempt to communicate directly a brain with a computer. This is of the utmost interest for people with severe motor disabilities, who cannot use the standard communication devices like keyboards or touchpads. Most usually, the BCI relies on non-invasive EEG (electroencephalogram) electrodes, which are attached to the scalp. The electrodes detect the EEG signals related to motor intentions, like the preparation to move the left hand, or just imagining making such movement. Once the EEG signal has been decoded, it can be used to move a cursor on the screen, or to execute commands in a computer. For instance, the intention to move the right hand can be used to move the cursor to the right, and so on.
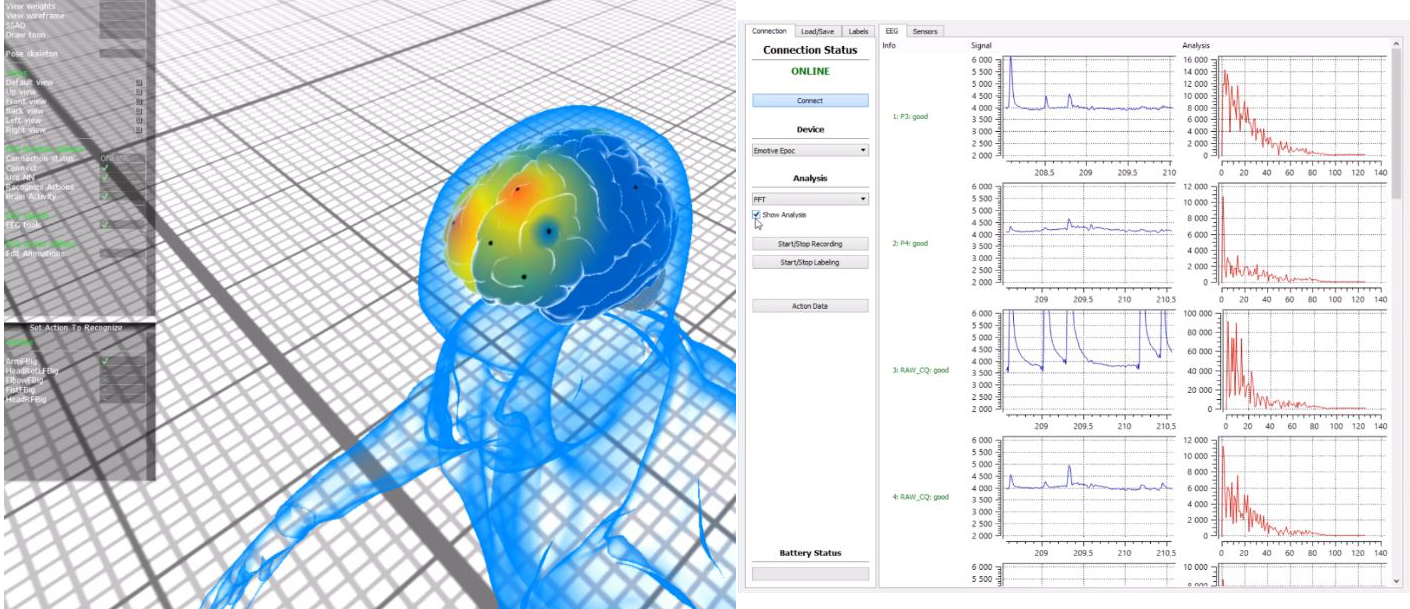
Decoding the EEG signal is not a straightforward task. The signal is very weak and many artifacts can be present (just blinking an eye may add noise to the signal). But most importantly, there is no simple function to map EEG signals to intentions. In addition, the mapping function can change from person to person, or even for the same person on different days. A common approach is to inductively learn the mapping function from hundreds of labelled data. For this task, inductive algorithms like Neural Networks or Support Vector Machines, can be used.
Current state of the applications
- EEG EPOC headset utilization
- C++, Qt application that covers basic funcionality (EPOC EDK included)
- Basic concept of GPU library for data manipulation
DNA Analysis (PG)
The sequence of the human genome is of interest in several respects. It is the largest genome to be extensively sequenced so far, being 25 times as large as any previously sequenced genome and eight times as large as the sum of all such genomes. Much work remains to be done to produce a complete finished sequence, but the vast trove of information that has become available through this collaborative effort allows a global perspective on the human genome. The genomic landscape shows marked variation in the distribution of a number of features, including genes, transposable elements, recombination rate, etc. There appear to be about 30,000–40,000 protein-coding genes in the human genome. However, the genes are more complex, with more alternative splicing generating a larger number of protein products.
We focused on applications of several data-mining and bio-inspired methods in the area of human DNA analysis. From the practical point of view, an effective and precise analysis and subsequent classification can play an important role in medical care. That is why we have established a close cooperation with the Department of Immunology, FM Palacky University & University Hospital Olomouc.
Current state of the applications
- Protein structure reader with support of PDB files
- Desktop application for data analysis and visualization
- CUDA based libraries for pattern matching

Network Science (EO)
Modern data sets can often be understood as some kind of network. Network Science is a cross-disciplinary domain focusing on the analysis and modelling of complex social, informational, biological and technological systems as networks.
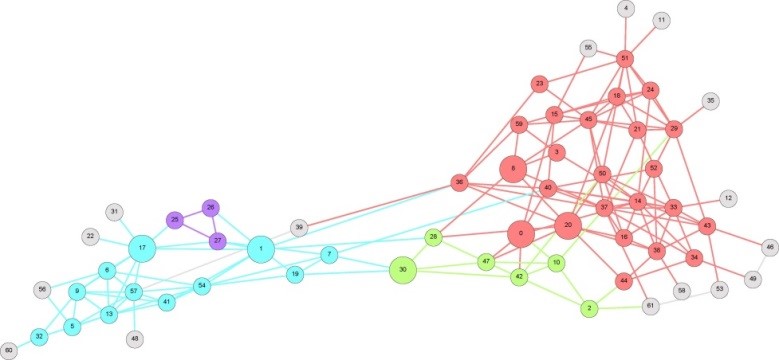
Understanding, analysing and modelling structure and dynamics of complex networks requires interdisciplinary approach including collaborations between physicists, mathematicians, computer scientists, biologists, etc. Our research is focused on the area of identification of community structure in networks. Detecting communities is hard and still open not well-defined problem. There exist many approaches suggested over the years differing in definition of community, in evaluation of partitions, etc. But, this is what makes this discipline very interesting.
Crytography (EO)
 Cryptography is currently facing new challenges arising from technological advances. E.g. new ways to construction of the cryptographic primitives are looking for. Almost all known constructions of cryptographic algorithms have made use of associative algebraic structures such as groups and fields. A possibility to use other algebraic structures, non-associative quasigroups, in cryptography is given in many papers published in last years. We are focused on quasigroups, their constructions, properties, and on cryptographic algorithms (based on quasigroups primitives), that are intended to encryption, to pseudorandom generators construction, to hash functions etc. We used softcomputing techniques (e.g. genetic algorithms) for generation of quasigroups with desired properties.
Cryptography is currently facing new challenges arising from technological advances. E.g. new ways to construction of the cryptographic primitives are looking for. Almost all known constructions of cryptographic algorithms have made use of associative algebraic structures such as groups and fields. A possibility to use other algebraic structures, non-associative quasigroups, in cryptography is given in many papers published in last years. We are focused on quasigroups, their constructions, properties, and on cryptographic algorithms (based on quasigroups primitives), that are intended to encryption, to pseudorandom generators construction, to hash functions etc. We used softcomputing techniques (e.g. genetic algorithms) for generation of quasigroups with desired properties.
Evolutionary fuzzy rules for data mining and knowledge discovery (PK)
Evolutionary fuzzy rules are a multi-paradigm soft computing model for data classification and regression. They combine the ability of nature-inspired symbolic regression (genetic programming) and fuzzy information retrieval to automatically create accurate models of various phenomena from data. They have been applied to various classification and regression tasks.
Bio-inspired methods for combinatorial optimization (PK)
Combinatorial optimization problems (e.g. permutation problems, subset selection problems) form a family of hard optimization tasks with a number of applications in operational research, telecommunications, feature selection, and planning. Powerful nature-inspired methods such as the differential evolution are well-suited to solve continuous problems. Their application to combinatorial optimization requires the development of new data structures and operators to facilitate efficient meta-heuristic search for good solutions.
Parallel and distributed meta-heuristics (PK)
The advent of new massively parallel hardware platforms such as floating-point accelerators, multi and many-core processors, and e.g. cloud computing represents an opportunity for large scale application of nature-inspired meta-heuristic methods that are implicitly parallel and can be efficiently parallelized. However, the different properties of different platforms and tools pose a number of challenges for the design of efficient parallelization strategies for different nature-inspired methods.